Maximize insights in Oracle Analytics Cloud with Data Lakehouses Part 2 - The Data Warehouse


In the first part of this series, I discussed what a Data Lake is. In a nutshell, it is a logical collection of files stored in object storage. These can be csv, pdf, imagines or what I call semi-structured data files like parquet and Iceberg. This post will describe the second part of a Data Lakehouse, the Data Warehouse. Combined they will be used to create a single data location for all types of analytical work loads like AI, ML, data visualization and reporting.
The term Data Warehouse was originally coined by Bill Inmon in his groundbreaking book from 1988, Building the Data Warehouse. As described in a retrospective he wrote in 2022 about his initial work; in the late 80s, a database was defined as "a single source of data for all processing." Bill challenged that notion and declared that there were two types of databases, transactional databases and analytical databases. Despite all the changes in technology, 36 years later this is still the case.
Over the past 36 years, the technology and techniques for building transactional and analytical databases have evolved considerably. However, their core functions remain unchanged. Transactional databases are designed to efficiently handle data processing tasks, while analytical databases are tasked with analyzing this transactional data to generate valuable insights for users.
Oracle offers two flavors of its Serverless Cloud Databases: Autonomous Transaction Processing (ATP) and Autonomous Data Warehouse (ADW) to meet those diverse needs. Although both are based on Oracle's robust database engine, they are optimized for different use cases.
Autonomous Transaction Processing (ATP) is ideal for transactional workloads, optimized for high-volume data inputs and OLTP applications. It excels in rapid query processing and efficient data manipulation, making it perfect for enterprise applications. ATP ensures high availability, scalability, and security, while automating routine tasks like patching, backups, and tuning.
Autonomous Data Warehouse (ADW) is designed for analytical workloads, optimizing complex queries and data analysis on large datasets. It suits data visualization, reporting, and data science applications, excelling in data aggregation, complex SQL queries, and parallel processing for quick reporting and analysis without manual tuning.
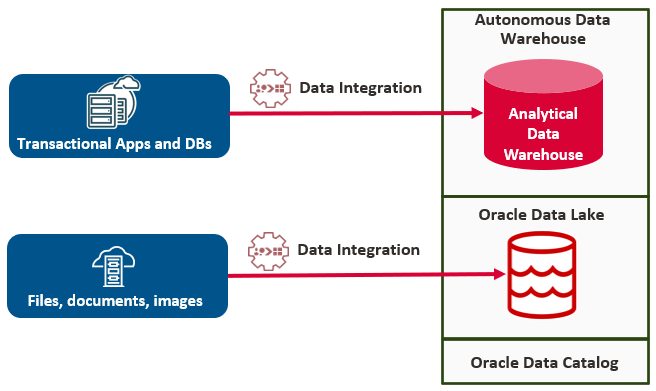
How does this fit in a Data Lakehouse architecture? Enterprise applications typically store data in transactional databases. Moving this data and optimizing it for analytics is a long-established technique that has been effectively used for decades. Data visualization and reporting tools are optimized for data warehouse databases instead of using Data Lakes or transactional databases as the source. This optimization enhances performance and enables detailed data exploration across various data domains.



