What is the Oracle Intelligent Data Lake (IDL)?


The Intelligent Data Lake was one of my key takeaways from Oracle CloudWorld 24. So what is it, and why does it matter? The answer to the former is that the Intelligent Data Lake (IDL) is Oracle's solution to building a comprehensive Data Lakehouse platform using modern data management tools. As you can see below, the IDL is a four-layer architecture. I will briefly go through each layer, starting on the data layer as everything builds upon that. I will deep-dive into each layer in later posts.
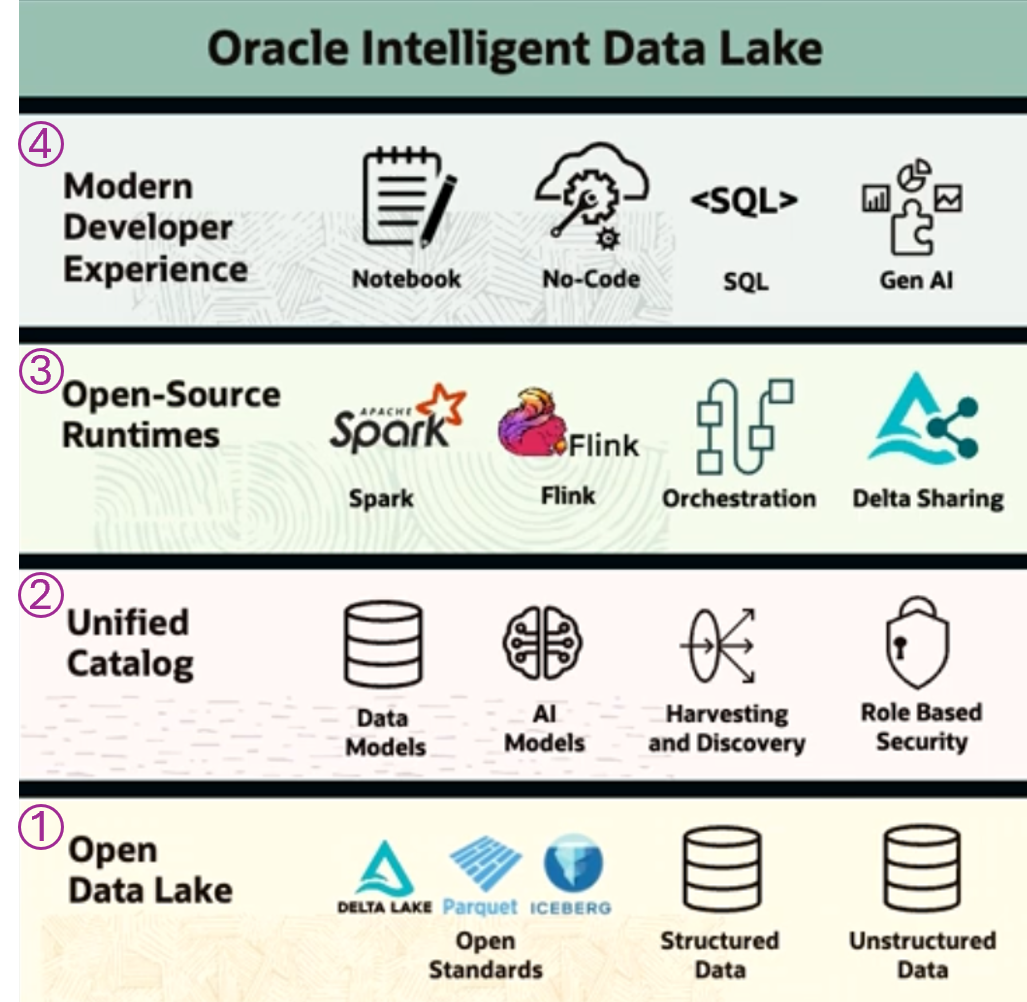
Layer 1: Open Data Lake
The Open Data Lake contains three main types of data:
- Open Source Data formats: These open source data file formats include Apache Parquet, Delta Lake, and Apache Iceberg and are commonly used to create "tables" in a Data Lake.
- Structured Data: This is your standard relational database data. It can be one or more different databases and isn't necessarily an Oracle Database.
- Unstructured Data: Files of any type, including documents, Pictures, XML files, Audio, Video, and CSV files. These differ from the Open-Source Data formats as those are structured and designed to perform analytical operations directly (e.g., Delta Lake SQL statements).
Layer 2: Unified Catalog
The Unified Catalog contains the Open Data Lake's metadata using the Oracle Data Catalog platform. This layer defines and stores data security, and enterprise AI models will also be stored there.
Layer 3: Open-Source Runtimes
The heavy hitter here is Apache Spark. It will be the main workhorse for data integration. The massively parallel nature of the platform allows for data virtualization in addition to data movement. As long as the data is registered in the Unified Catalog, the system can real-time query a third-party cloud data object (e.g., GCP BigQuery table). I will go over these in my deep dive, but in a nutshell, Apache Flink is primarily used as a stream-processing framework, and Delta Sharing is an open-source protocol to share Delta Lake files.
Layer 4: Modern Developer Experience
The modern developer experience is the approach of allowing users to leverage their tools of choice. Data Scientists will want to use things such as Jupyter Notebooks to write complex ML models, whereas others will simply want to interact with the data using SQL (e.g. Spark SQL). More to come.
What's Next?
This was a quick run down of the 4 layer Oracle Intelligent Data Lake architecture. Hopefully it helped give you an idea on what each of these layers represents. Be on the look out for my posts where I deep dive into these further.



